Differentiating a Queue Model
In this example, we use GradInf to develop a new, lower-variance gradient estimator for an M/M/C queue model.
Setup
This example needs the following imports.
{-# LANGUAGE RebindableSyntax #-}
{-# LANGUAGE ScopedTypeVariables #-}
{-# LANGUAGE TypeApplications #-}
import Prelude
import Data.Functor.Identity
import Control.Monad
import Control.Monad.Bayes.Sampler.Lazy
import System.Random (setStdGen, mkStdGen)
import Numeric.GradInf
import Numeric.GradInf.Inference.Base
import Numeric.GradInf.Primitives.DeterministicPrimitives
import Numeric.GradInf.Primitives.FlipCRN
import Numeric.GradInf.Primitives.IterateP
-- $setup (use a fixed seed)
-- >>> setStdGen (mkStdGen 42)
- Primitives: we import
DeterministicPrimitives,FlipCRN, andIteratePfromNumeric.GradInf.Primitives. - Extensions: the language extension
RebindableSyntaxallowsgrad-infto handle if-then-else statements in our code.
We also define a helper function for analyzing gradient estimates.
meanAndVariance :: [Double] -> (Double, Double)
meanAndVariance xs = do
let n = length xs
let mu = (sum xs) / (fromIntegral n)
let var = (sum (map (\x -> (x - mu) * (x - mu)) xs))
/ (fromIntegral (n - 1))
(mu, var)
Writing the Model
We first write the Markov kernel for the model, which simulates a single queuing event.
queueKernel :: forall m d i b mat.
(DeterministicPrimitives d i b mat, FlipCRN m d b)
=> d -> i -> m i
queueKernel theta x = do
let p = theta / (theta +
if (isGreater x 25) :: b then 25 else toDouble x)
b :: b <- flipCRN p
let x' = if b then x + 1 else x - 1
return x'
Here, note that:
-
We program polymorphically with respect to types
m d i b mat, which are generic stand-ins for the probability monad, doubles, integers, booleans, and matrices, respectively. -
The
DeterministicPrimitives d i b matconstraint encompasses the usual Haskell constraints (Num d,Floating d,Integral i, etc.), and also provides new primitives in cases where existing Haskell options are not sufficiently generic (e.g.toDouble :: i -> d,isGreater :: d -> d -> b, and if-then-else statements that accept the generic Booleanb). -
The
FlipCRN m d bconstraint provides a probabilistic primitive for flipping a coin, with typeflipCRN :: d -> m b. -
The
IterateP m iconstraint provides repeated Markov steps with resampling between iterations.
We now complete the M/M/c model by iterating the kernel n times to
simulate n queuing events.
queueModel :: forall m d i b mat.
( DeterministicPrimitives d i b mat
, FlipCRN m d b, IterateP m i )
=> Int -> d -> m d
queueModel n theta = do
x <- iterateP (queueKernel theta) 0 !! n
return (toDouble x)
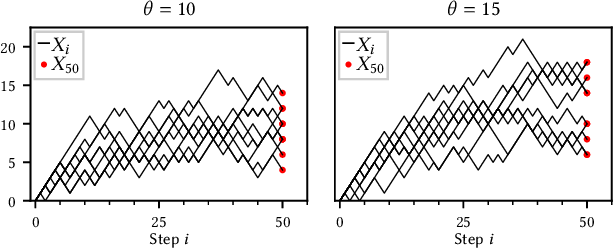
Let’s take a few samples from the model at θ = 10 and n = 50.
getSamplesLow :: Sampler [Double]
getSamplesLow =
replicateM 5 (queueModel (50 :: Int) (10 :: Double))
-- |
-- >>> sampler getSamplesLow
-- [8.0,6.0,6.0,14.0,12.0]
Let’s now take a few samples from the model at θ = 15 and n = 50.
getSamplesHigh :: Sampler [Double]
getSamplesHigh =
replicateM 5 (queueModel (50 :: Int) (15 :: Double))
-- |
-- >>> sampler getSamplesHigh
-- [12.0,10.0,10.0,18.0,18.0]
The following plot illustrates sample paths of the M/M/c model at each of these parameters.
Differentiating the Model
Let us now run GradInf on this program, first using an inference scheme based on stratified importance resampling (SIR).
getGradientEstimateSIR :: Int -> Double -> Sampler Double
getGradientEstimateSIR n theta =
fmap runIdentity
(gradInfAD (queueModel n . runIdentity)
(stratifiedImportanceResamplingInferenceAlg 1)
(Identity theta))
Let’s print a few samples from getGradientEstimateSIR and their
empirical mean and variance.
printSamplesSIR :: Int -> Double -> IO ()
printSamplesSIR n theta = do
samples <- sampler
(replicateM 5 (getGradientEstimateSIR n theta))
print samples
-- |
-- >>> printSamplesSIR 50 15.0
-- [1.5151844834603452,0.0,0.0,1.2422897134382118,1.260931988773068]
printMeanAndVarianceSIR :: Int -> Double -> IO ()
printMeanAndVarianceSIR n theta = do
samples <- sampler
(replicateM 100 (getGradientEstimateSIR n theta))
print (meanAndVariance samples)
-- |
-- >>> printMeanAndVarianceSIR 50 15.0
-- (0.6459758088306011,0.5114738156744449)
Next, we apply GradInf using an inference scheme based on variable elimination (VE), again printing a few samples and their empirical mean and variance.
getGradientEstimatesVE :: Int -> Double -> Sampler Double
getGradientEstimatesVE n theta =
fmap runIdentity
(gradInfAD (queueModel n . runIdentity)
variableEliminationInferenceAlg
(Identity theta))
printSamplesVE :: Int -> Double -> IO ()
printSamplesVE n theta = do
samples <- sampler
(replicateM 5 (getGradientEstimatesVE n theta))
print samples
-- |
-- >>> printSamplesVE 50 15.0
-- [0.8083904869311099,0.5604225142545218,0.62754459545659,0.7157384480204139,0.33997920418797795]
printMeanAndVarianceVE :: Int -> Double -> IO ()
printMeanAndVarianceVE n theta = do
samples <- sampler
(replicateM 100 (getGradientEstimatesVE n theta))
print (meanAndVariance samples)
-- |
-- >>> printMeanAndVarianceVE 50 15.0
-- (0.6532304786017948,2.211323360216621e-2)
Observe that while the gradient estimator remains unbiased, changing the inference algorithm can result in a significant reduction in variance.